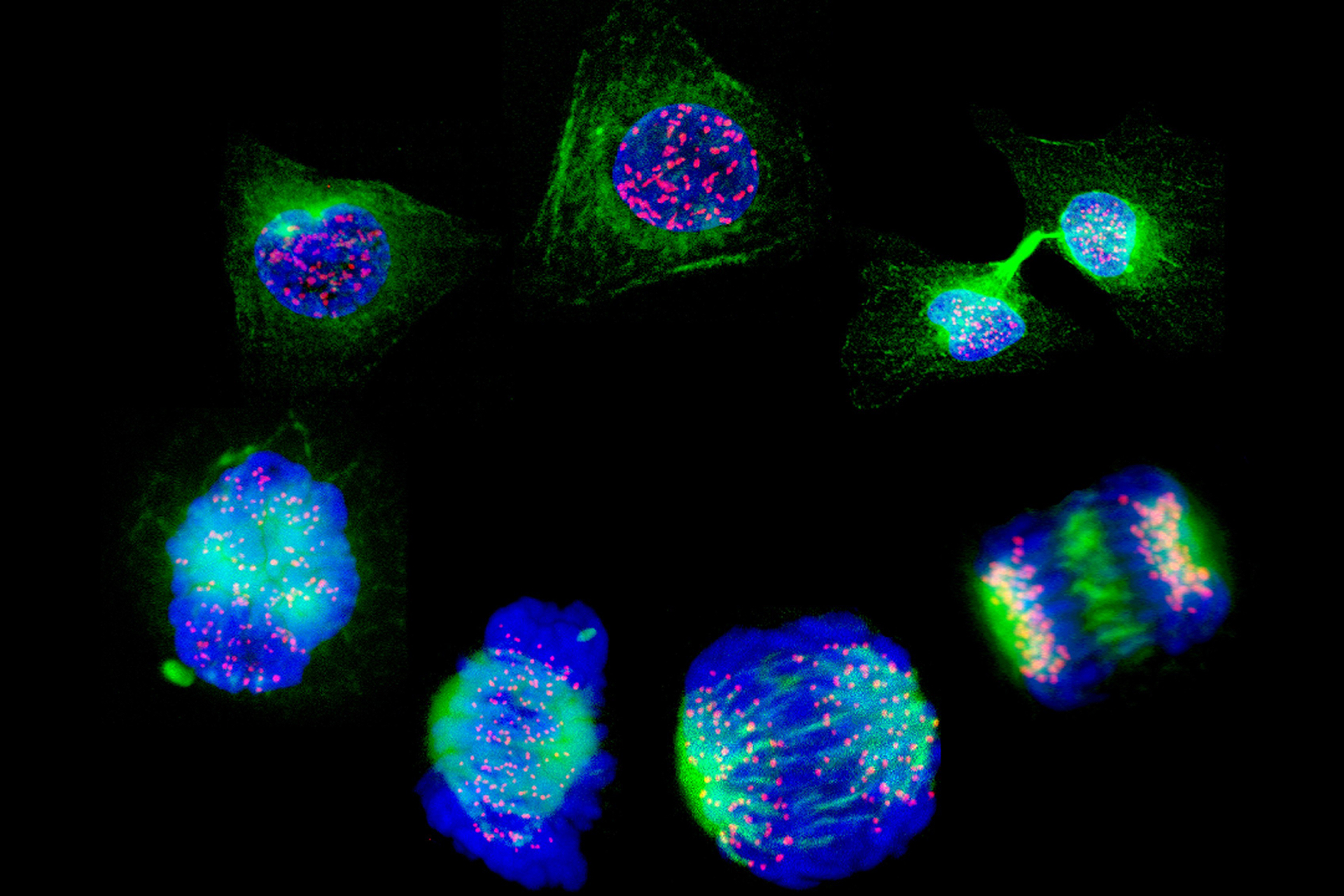
A new machine learning tool has been developed to help measure the efficiency of a specific type of genome editing, and identify what affects the rate of insertion of a genetic sequence.
Prime editing is a genome editing approach which allows the insertion of short, single-stranded DNA sequences into a single point in the genome (see BioNews 1021). As with other forms of genome editing, there are questions about the accuracy and efficiency of the changes it makes. A recent study in Nature Biotechnology by researchers based at the Wellcome Trust Sanger Institute, Cambridge, sought to quantify the effect of DNA sequence length, nucleotide composition and secondary structure on the efficiency of insertion at the target site in the genome using different prime editing systems.
'The variables involved in successful prime edits of the genome are many, but we're beginning to discover what factors improve the chances of success', said co-first author PhD candidate Jonas Koeppel. 'Length of sequence is one of these factors, but it's not as simple as the longer the sequence the more difficult it is to insert'.
Prime editing is a modification of the CRISPR/Cas9 genome editing approach, which use enzymes to 'cut' DNA at specific sequences, using a short RNA sequence as a label to find the place to cut. However this can result in the loss of expression of a gene, as the sequence that codes for that protein is lost. Prime editing uses a version of Cas9 that doesn't completely cut the DNA strand in two, instead only nicking one of the two chains. This allows another enzyme to insert a desired sequence provided at the same time. This flexibility allows scientists and clinicians to try and treat a greater number of diseases, by correcting mutations that cause disease instead of just removing unwanted genes.
Researchers investigated the factors affecting the success of different prime editing systems by targeting insertions of 3604 DNA sequences of various lengths into four different sites in the genome of three different human cell lines. By sequencing the DNA of the treated cells the team were able to identify which sequences and which editing systems worked most efficiently, and then developed an algorithm which can be used to predict the efficiency of insertion of different sequences in future.
'Put simply, several different combinations of three DNA letters can encode for the same amino acid in a protein. That's why there are hundreds of ways to edit a gene to achieve the same outcome at the protein level,' explained co-author PhD candidate Juliane Weller. 'By feeding these potential gene edits into a machine learning algorithm, we have created a model to rank them on how likely they are to work. We hope this will remove much of the trial and error involved in prime editing and speed up progress considerably.'
Sources and References
-
Machine learning helps determine success of advanced genome editing
-
Prediction of prime editing insertion efficiencies using sequence features and DNA repair determinants
-
Say goodbye to trial and error: New machine learning tool improves efficiency of prime editing
-
Improved efficacy of advanced genome editing with machine learning
Related Articles
Genome editing screen finds cancer mutations faster
A genome editing technique that allows researchers to test thousands of different mutations that might affect how cancer cells behave has been developed...
Event Review: Modifying Humans – Is global governance of genome editing possible?
The Centre for Bioethics and Harvard Medical School, Massachusetts, presented a fascinating talk on the opportunities for great medical advancements, and grave harm, presented to researchers by CRISPR/Cas9 and other apporaches to genome editing...
New method giving insight into DNA repair pathways could improve genome editing
In-depth mapping of DNA repair mechanisms of the double-stranded and single-stranded breaks required for genome editing, could enhance the efficacy of these approaches, new research has revealed...
New 'prime' genome editing offers promise
An improved genome editing method could potentially correct 89 percent of known genetic defects causing disease, US scientists say.
Leave a Reply
You must be logged in to post a comment.